
首个统一多模态模型评测标准,DeepSeek Janus理解能力领跑开源,但和闭源还有差距
首个统一多模态模型评测标准,DeepSeek Janus理解能力领跑开源,但和闭源还有差距统一多模态大模型(U-MLLMs)逐渐成为研究热点,近期GPT-4o,Gemini-2.0-flash都展现出了非凡的理解和生成能力,而且还能实现跨模态输入输出,比如图像+文本输入,生成图像或文本。
来自主题: AI技术研报
9169 点击 2025-04-10 10:20
 搜索
搜索
统一多模态大模型(U-MLLMs)逐渐成为研究热点,近期GPT-4o,Gemini-2.0-flash都展现出了非凡的理解和生成能力,而且还能实现跨模态输入输出,比如图像+文本输入,生成图像或文本。
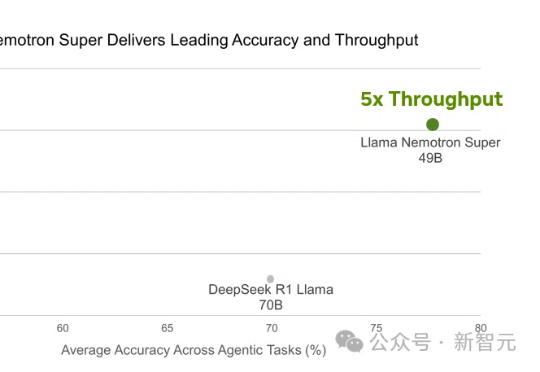
Llama 4刚出世就被碾压!英伟达强势开源Llama Nemotron-253B推理模型,在数学编码、科学问答中准确率登顶,甚至以一半参数媲美DeepSeek R1,吞吐量暴涨4倍。关键秘诀,就在于团队采用的测试时Scaling。
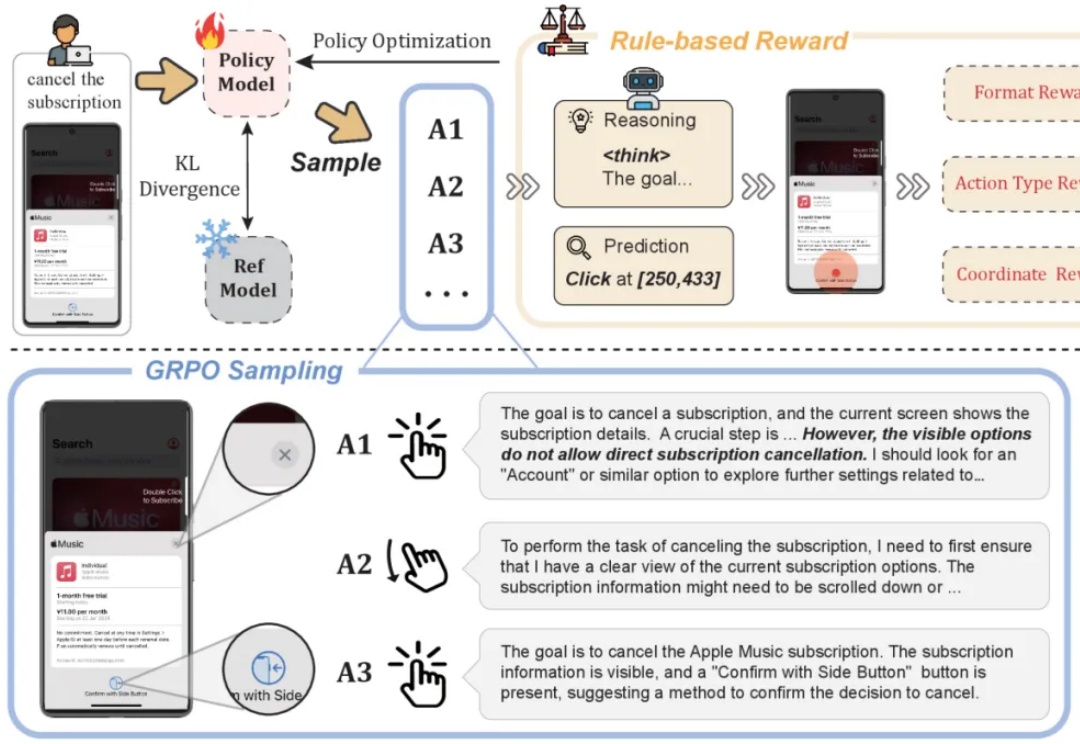
基于规则的强化学习(RL/RFT)已成为替代 SFT 的高效方案,仅需少量样本即可提升模型在特定任务中的表现。
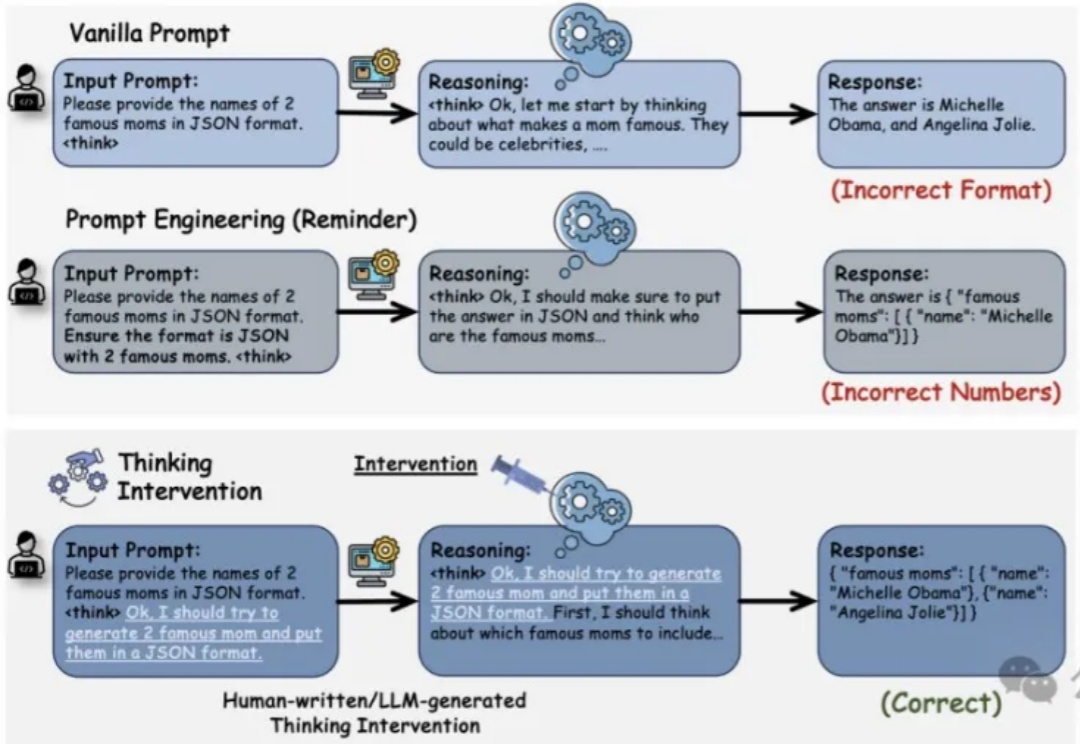
推理增强型大语言模型LRM(如OpenAI的o1、DeepSeek R1和Google的Flash Thinking)通过在生成最终答案前显式生成中间推理步骤,在复杂问题解决方面展现了卓越性能。然而,对这类模型的控制仍主要依赖于传统的输入级操作,如提示工程(Prompt Engineering)等方法,而你可能已经发现这些方法存在局限性。

原生多模态Llama 4终于问世,开源王座一夜易主!首批共有两款模型Scout和Maverick,前者业界首款支持1000万上下文单H100可跑,后者更是一举击败了DeepSeek V3。目前,2万亿参数巨兽还在训练中。
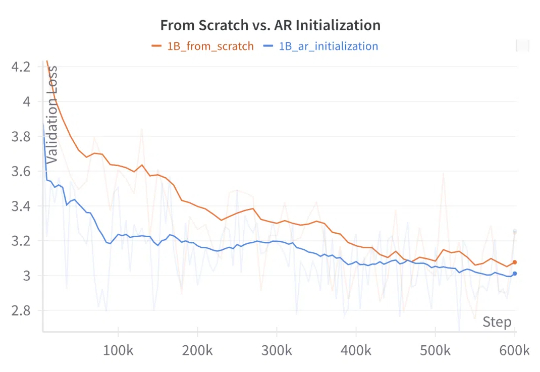
语言是离散的,所以适合用自回归模型来生成;而图像是连续的,所以适合用扩散模型来生成。在生成模型发展早期,这种刻板印象广泛存在于很多研究者的脑海中。

DeepSeek新论文来了!在清华研究者共同发布的研究中,他们发现了奖励模型推理时Scaling的全新方法。DeepSeek R2,果然近了。
随着DeepSeek R1、OpenAI GTP-4o、Antropic Claude3.7、xAI Grok3纷至沓来,AI大模型已然变成巨头的游戏,“百模大战”也成为了过去式。到了2025年,让用户先把AI用起来,也已经成为了一众厂商的共识。
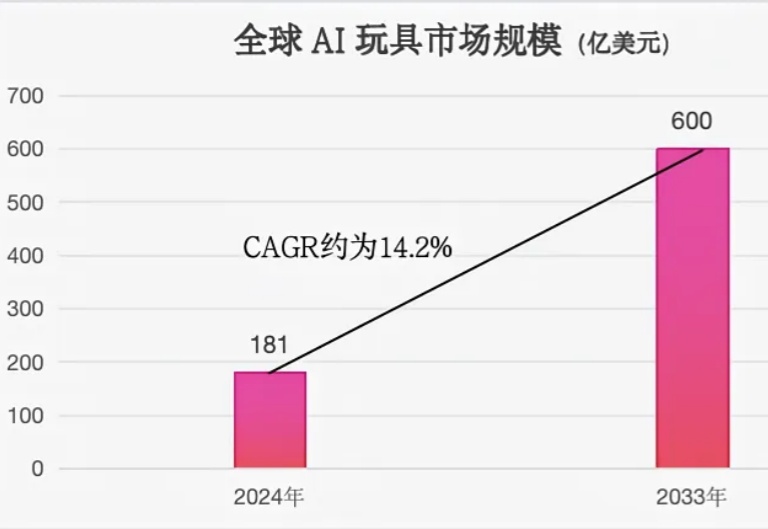
2025 年,DeepSeek 爆火带动传统产品的智能化升级,如传统玩具向 AI 玩具转型。央视新闻调查数据显示,2025 年 1 月,国内某电商平台面向 3-6 岁儿童的 AI 早教玩具销量环比增长 6 倍。咨询公司 IMARC 的预测数据显示,2024 年全球 AI 玩具市场规模已达 181 亿美元,预计到 2033 年将增长至 600 亿美元。

众所周知,DeepSeek R1 这种模型在推理任务上很能打,尤其是在数学和编程这些逻辑性强的领域。那么我们能直接把这种强大的推理能力搬到 DeepSearch 这种需要动态规划、多轮交互的深度搜索场景里吗?